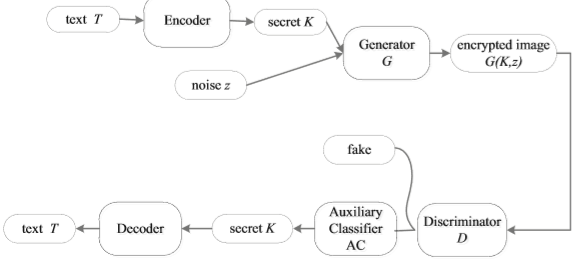
论文“Generative Steganography Based on GANs”(下载地址)提出了一种基于生成对抗网络(Generative Adversarial Net)的生成式隐写方案,属于无载体(coverless)信息隐藏,即载体无修改。传统的载体合成方案基于载体选择,由于数码相机很难获取相同场景的不同采样,传统方法具有局限性。而这种方式则是直接利用秘密信息生成载体,不存在这个问题(作者说)。 方案简述如下:发送者将文本T编码为秘密信息K,编码方式是词典中图像库类别标签与二进制比特流的映射。使用秘密信息K和噪声Z输入GAN,输出自然图像(图中记作加密图像)。接收者先判别图像真假(一般会被判为真),再使用辅助分类器分类,得到类别标签,对照词典(与发送者共享),从而提取出秘密信息。
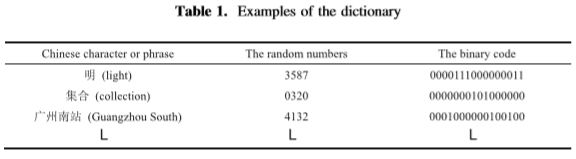
一个具体实例:假如文本信息T是“明天8点广州南站集合(Tomorrow 8:00 Guangzhou South Station Collection)”,查词典得到K=“00100100000 10000001001000000000101000000”。这串比特流(1表示该比特位置有类别标签,0表示无)对应的7个类别标签(比特流中有7个1)依次是Attractive,Bangs,Brown_Hair,Heavy_Makeup,Mouth_Slightly_Open,Smiling和Wavy_Hair。
从左到右的图像,标记为1-8。图1是只输入噪声,即无类别标签。图2是+Attractive,图3是+ Attractive,+ Heavy_Makeup,…图8加了所有7个标签。

对于容量问题,本实验训练图像库中,每幅图像的类别标签是40个,即可隐藏40比特信息。每个中文字符占据16bit,每个图像只能携带2个中文字符。提高每个图像的平均隐藏容量的方法有两个,(1)增加词典中单词的平均长度,(2)使用多个小分辨率的图像组成具有较大分辨率的组合图像(joint image)。 对于安全问题,由于在通信之前发送方和接收方共享随机噪声z,相同的真实样本数据集x,相同的类标签和相同的训练步骤来训练GAN以获得相同的生成器和鉴别器。共享词典以便于接收方提取秘密信息。这些信息看守者无从得知,且截获的图像是GAN生成的自然图像,没有可检测的典型统计特征,所以看守者无法得到秘密信息。 局限性是发送方和接收方在通信前需要传输共享的信息量过大(用于训练GAN的图像库、共享词典等),让人想起二战期间用到的密码本。