略读:动机、方法、结果
论文简介
- 题目《Regularization with Latent Space Virtual Adversarial Training》,通过在潜在空间里施加扰动,生成 AE ,使分类器对AE具有鲁棒性。
- 发表状态:ECCV 2020
背景
- 众所周知,正则化 是一种典型的 避免过拟合 的方法。
一致性正则化(Consistency Regularization)- 一种 基于扰动 的方法
- 基础假设是 局部一致性(local consistency):输入空间中的附近点 可能 有相同的输出。
- 在学习过程中 扰动输入,迫使模型对它们具有鲁棒性。
- 引入正则化项(一致性代价): 使得 对于 带/不带 有扰动的输入,模型的输出 都是一致的。
- 可以在
没有类标签的情况下work
- 在
一致性正则化方法中,虚拟对抗性训练(VAT)效果显著。- VAT 通过在 输入空间 注入扰动 而生成 对抗样本 进行训练
- 这个 扰动不是 随机,而是 朝着 对模型输出 最不利影响的方向(比如 分类预测) 产生。
现有方法存在的问题
- 但是,VAT只能 在输入数据点周围很小的区域内 生成对抗样本,这限制了 对抗样本 搜索空间。
本文应对方法
- 为了解决这个问题,本文提出了LVAT(潜在空间VAT),在 潜在空间 (不是输入空间)中注入扰动。 生成 更有效的 对抗样本。
- 潜在空间 由生成模型建立,比如VAE和Glow。
- LVAT利用潜在空间 灵活地生成对抗样本,从而产生更多的不利影响,实现更好的一致性正则化,增强分类器的泛化能力。
实验效果-初探
- 对于 有监督和半监督学习场景,本文 在 SVHN和CIFAR-10数据集 图像分类任务 中 评估了LVAT的性能。
- 评估发现,本文方法优于 VAT和其他最新方法。
精读:方法、实验
前置知识→本文方法
- 分类预测
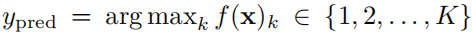
- VAT
VAT中,一致性代价( consistency cost)是:
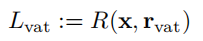 其中,
其中,
.png) 对抗扰动r
对抗扰动r
.png)
- Transformer
- 这里transformer指的是,以VAE和Glow为代表的生成模型。
- x是输入空间,z是潜在空间,Enc表示x->z,Dec表示z->x。
- 为了解决VAT问题,本文做法:LVAT
- VAT的问题是Local Constraint:
- 即,只能 在输入数据点x周围很小的区域内 生成对抗样本,这限制了 对抗样本 搜索空间。
- 为了消除Local Constraint,本文提出方法是LVAT,
- 即,在潜在空间中计算对抗扰动,从而灵活生成对抗样本。
- 具体地,把公式(4)应用到潜在空间z,
- 在z中计算对抗扰动r_lvat,
- 在z中得到”对抗潜在表示” z_adv = z + r_lvat,
- 在x中得到”真正对抗样本” x_adv = Dec(z_adv)。
- LVAT中,一致性代价是:
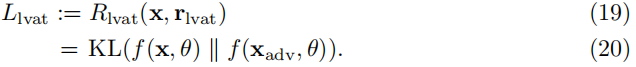
- 其中,对抗样本X_adv是这样来的:

-
潜在空间z里的对抗扰动r_lvat是这样算的
.png)
- 所以,在生成对抗样本AE时,VAT和LVAT最大区别是,
- VAT是在x空间计算扰动,直接生成AE;
- LVAT是在潜在空间z计算扰动,通过transformer(生成模型)映射回x空间,从而得到AE。
- VAT的问题是Local Constraint:
- 总体框架图
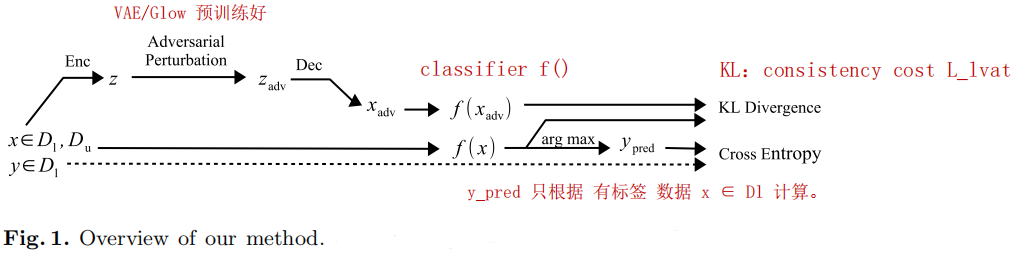
- 图1中,D_l是有标签数据,D_u是无标签数据。
- 注意:Transformer和分类器要分开单独训练。
- 分类器损失组成
- 分类器f的结构,和一些previous works一样。
- f的损失L:两部分
- L_sl: 监督损失(交叉熵),
- L_lvat:一致性代价(正则项),提高泛化性
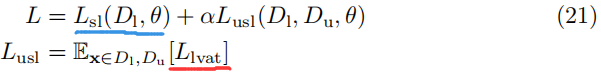
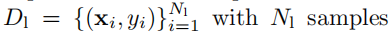
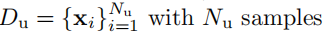
实验结果
- 数据集
- SVHN和CIFAR-10
- (32×32彩色图像,10种类),
- 包括
增强数据集
- 在图像分类任务中,评估LVAT方法
- (监督+半监督 情况)
- SVHN和CIFAR-10
- 分类性能-准确率
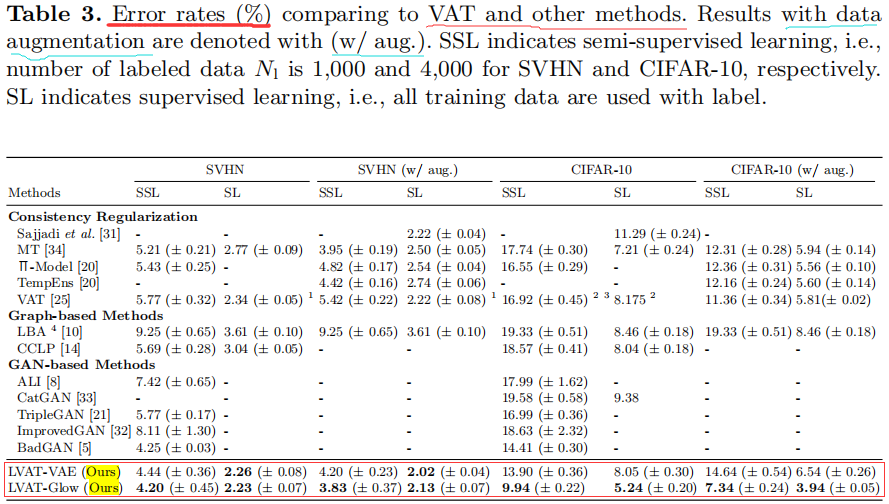
- 表格说明:
- 表格3是 LVAT和 其它方法(VAT等)的对比,
- 表格4是 LVAT和 结合方法(MT, Π-Model, TempEns, VAT选择性组合) 的对比。
- 结论:
- 大部分情况下,LVAT效果 优于 其它/结合方法。
- 表格3
- 表格4
- 表格说明:
- 对抗样本-扰动幅度
- LVAT/VAT AE 幅度 区别
- LVAT 在
较宽幅度范围内生成AE(对抗样本), - 而VAT里每个AE都是以
相同幅度$ϵ_vat$生成的。
- LVAT 在
- 如下直方图:
- 横轴是
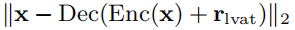 (相当于VAT中的$ϵ_vat$),
(相当于VAT中的$ϵ_vat$), - 纵轴是 频率。(红色的数据,是我补充画上去的)
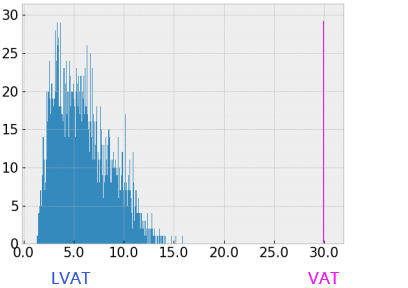
- 横轴是
- LVAT/VAT AE 幅度 区别
- 对抗样本-视觉效果
- LVAT/VAT AE 图像质量 区别
- 如图3,VAT的AE图像有伪影,
- 而LVAT的AE图像相比之下要真实一些。
- 原因:
- 对于VAE/Glow构造的潜在空间p(z),p(z)里高密度区域中的点对应的就是真实图像。
- 所以,只要扰动幅度ϵ_lvat不太大,“对抗潜在表示”z_adv也对应的是真实图像。

- LVAT/VAT AE 图像质量 区别
- Glow在本文实验里起到的作用
- 合理选择transformer(生成模型),比如Glow,有利于提高本文LVAT实验效果。
- 1)图像质量:和VAE相比(即使没有扰动,重建图像都是模糊的),Glow可以重建出更加清晰的图像(图(d)中 第二行),
- 2)分类准确率:LVAT-Glow在CIFAR-10上的分类性能非常好。
- 合理选择transformer(生成模型),比如Glow,有利于提高本文LVAT实验效果。